2024-09-01
开云谁是最会做题大模型?“高考评测”来了—新闻—科学网
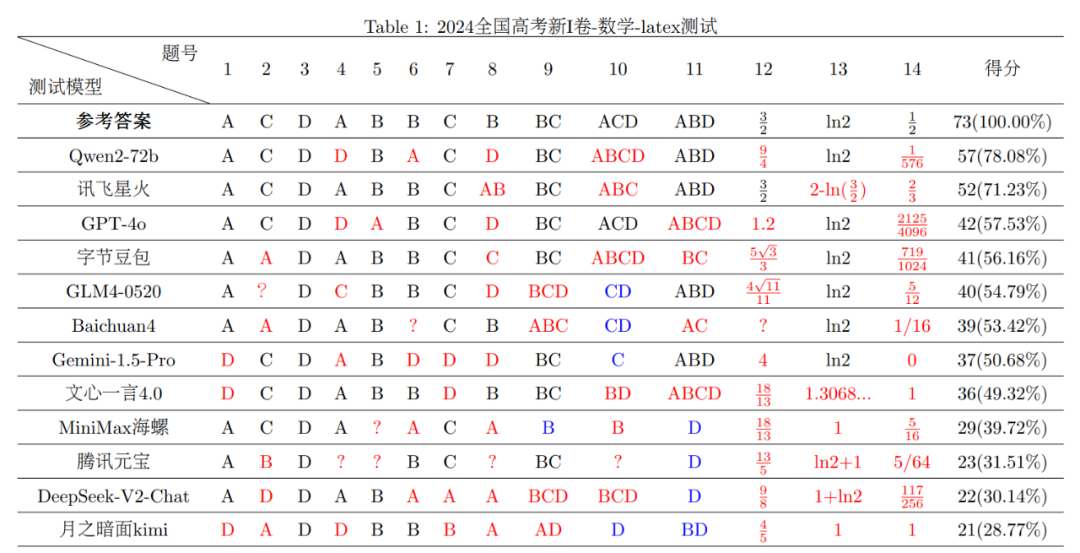
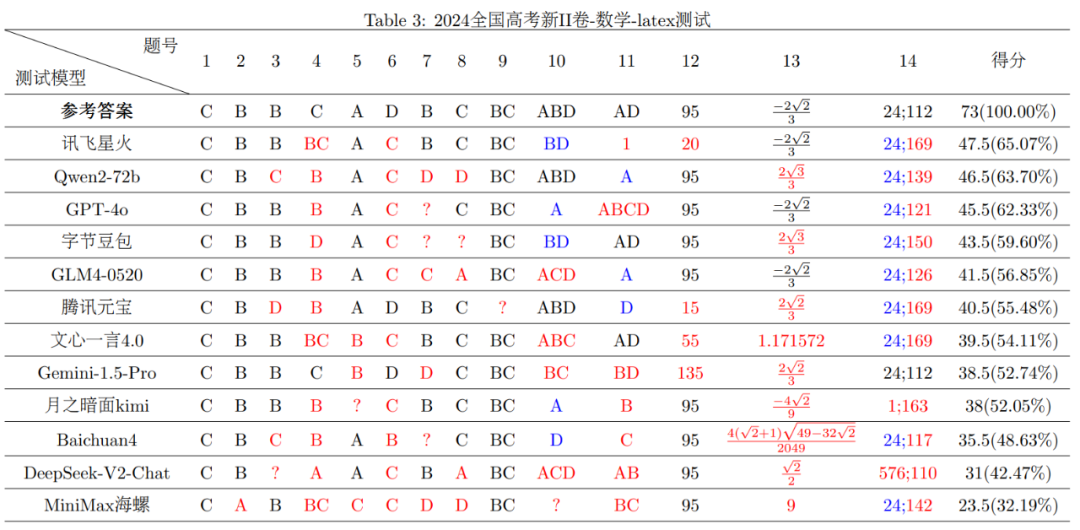
2024年天下高考的“硝烟”方才散去不久,“年夜模子考生”就被抓回来从头“做题”了。 市道上涌现出的年夜模子产物让人目炫狼籍,缭绕“年夜模子技能哪家强”的会商不绝在耳,各色名目的年夜模子评测应运而生。作为海内最权势巨子的测验之一,高考笼罩各种学科及题型,同时于开考前属在“绝密”,很是合适用来作为考察年夜模子智能程度的评测东西,可谓年夜模子综合威力的“试金石”。 连日来,一些专业机构纷纷了局,使用市道上常见的年夜模子产物如通义千问、字节豆包、讯飞星火、文心一言、腾讯元宝、Kimi等作为“考生”,缭绕“年夜模子高考测试”患上出了一系列成果,为人们更好地相识年夜模子产物的机能以及特色提供了参考样本。 动静出自上海人工智能试验室旗下司南评测系统OpenCompass对于7个开源年夜模子举行的高考“语数外”全卷威力测试。据OpenCompass在6月19日发布的评测成果,年夜模子的语文、英语测验程度还不错,但数学都不迭格,最高分也只要75分(满分150分)。 到场OpenCompass这次高考测试的年夜模子,别离来自阿里巴巴、零一万物、智谱AI、上海人工智能试验室、法国Mistral的开源模子。OpenCompass称,因没法确定闭源模子的更新时间,这次评测没有纳入商用闭源模子,仅引入GPT-4o作为评测参考。 不外,复旦年夜学天然言语处置惩罚(NLP)试验室LLMEVAL团队掌管的高考数学评测显示,年夜模子数学成就欠安的成果,可能缘在“打开体式格局不合错误”。 起首,LLMEVAL团队拔取了2024年高考新I卷、新II卷数学试卷的主观题(单选、多选以及填空题,共73分)来评测,患上出了差别的结论。使用主观题测试年夜模子的利益是,对于就是对于,错就是错,成果一目明了。同时客观题因为解题要领、思绪存于差异,具备必然的客观性,假如成果不准确,很难主观地评出步调分。 其次,这次年夜模子“考生”增长到12个:阿里巴巴Qwen2-72b、讯飞星火、GPT-4o、字节豆包、智谱GLM4-0520、百川智能Baichuan四、googleGemini-1.5-Pro、文心一言4.0、MiniMax海螺、腾讯元宝、月之暗面Kimi、DeepSeek-V2-Chat。 别的,他们于评测中发明,数学问题的差别格局的提醒输入(Prompt)对于年夜模子机能影响很年夜。于最初的评测中,LLMEVAL团队对于数学标题问题中的公式部门接纳了经由过程光学字符辨认(OCR)后输出的格局(本义符格局),最新一次评测则使用了Latex格局举行了横向对于比评测。 成果显示,年夜大都模子两次测试成果呈现较年夜差异,不外使用Latex格局后,年夜模子总体体现更佳:2024年天下高考新I卷、新II卷数学测试中,患上分率跨越50%的年夜模子产物数目由此前的5个以及6个升至7个以及9个。思量到Latex格局更切合人类现实使用年夜模子时所接纳的格局,LLMEVAL团队提议后续测试重要基在此格局。 详细而言,LLMEVAL团队使用Latex格局Prompt的测试成果显示,于2024天下高考新I卷数学测试中,阿里巴巴Qwen2-72b、讯飞星火的患上分率均跨越合格线(60%),别离为78.08%以及71.23%;于2024年天下高考新II卷数学测试中,讯飞星火、阿里巴巴Qwen2-72b以及GPT-4o的患上分率也凌驾了合格线,别离为65.07%、63.70%、62.33%。